

180-2308-6166
DeepSeek 和 OpenAI:全面分析其功能、性能和潜力| DeepSeek 系列
“
DeepSeek 的出现标志着人工智能发展的一个关键时刻,传统的监督学习范式正受到更加自主、自我进化的系统的挑战。这种转变不仅仅是为了创造更强大的人工智能模型,它还彻底改变了我们处理人工智能开发本身的方式。
”
DeepSeek-AI 开发的DeepSeek定位为OpenAI的直接竞争对手,它不仅代表了 AI 领域的又一新成员,而且是对人工智能学习、推理和发展方式的根本性重构。随着 AI 行业继续以前所未有的速度发展,DeepSeek 在强化学习和架构设计方面的创新方法正在为性能、效率和可访问性树立新的标杆。

DeepSeek 的出现标志着人工智能发展的一个关键时刻,传统的监督学习范式正受到更加自主、自我进化的系统的挑战。这种转变不仅仅是为了创造更强大的人工智能模型,它还彻底改变了我们处理人工智能开发本身的方式。
DeepSeek 的演变:全面概述
基础:DeepSeek-R1 系列
DeepSeek-R1 系列大胆突破了传统的 AI 开发方法,引入了两种突破性的模型,重新定义了机器学习的可能性:
DeepSeek-R1-Zero:纯强化学习的先驱
DeepSeek-R1-Zero 证明了纯强化学习在 AI 开发中的强大作用。与严重依赖监督学习和预标记数据集的传统模型不同,R1-Zero 踏上了自我发现和自主学习的旅程。这种方法可以比作孩子通过纯粹的经验而不是正式的指导来学习。
R1-Zero 的关键方面包括:
- 完全消除监督微调
- 自主发展推理能力
- 自然进化的自我验证机制
- 通过经验形成的独立解决问题的策略
- 反思能力的自然发展
虽然这种纯粹的强化学习方法具有卓越的推理能力,但它也面临着沟通清晰度和一致性的挑战——就像一位才华横溢的自学成才者,开发出了独特的信息处理和表达方式。
DeepSeek-R1:混合学习的演变
DeepSeek-R1 借鉴了 R1-Zero 的经验,代表了一种更为复杂的 AI 开发方法。该模型引入了一种混合学习方法,将结构化学习的优势与强化学习的创新能力相结合。
混合学习方法包括:
- 结构化基础建设
- 集成高质量冷启动数据
- 精心策划的初始训练集
- 特定领域知识的均衡组合
2. 高级强化学习
- 复杂的奖励模型系统
- 群体相对策略优化(GRPO)
- 人机交互反馈机制
- 迭代改进周期
3. 性能优化
- 增强推理效率
- 提高语言一致性
- 产出结构更加一致
- 卓越的解决问题能力
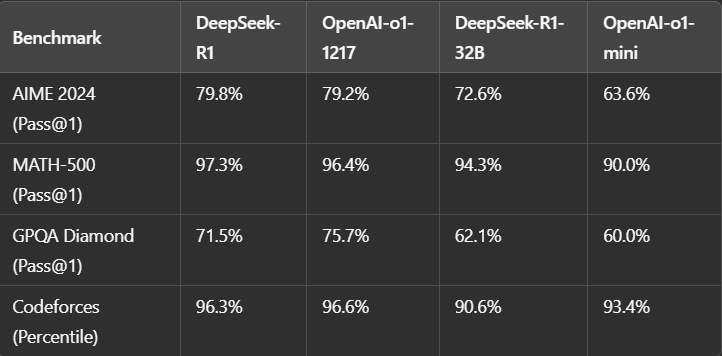
基准性能
DeepSeek-R1 在多个推理基准测试中表现出色:
下一代:DeepSeek-V3
DeepSeek-V3 代表了 AI 能力的一次巨大飞跃,引入了革命性的架构创新,突破了语言建模和 AI 处理的极限。
DeepSeek:详细的技术分析
DeepSeek-V3 代表了 AI 语言建模的重大飞跃,总共拥有 671B 个参数,每个 token 激活 37B 个参数。
它引入了多头潜在注意力 (MLA)、DeepSeekMoE 架构、多令牌预测和 FP8 混合精度训练,以提高效率和经济高效的训练。
多头潜在注意力(MLA)
多头潜在注意力机制代表了人工智能模型处理信息方式的重大进步。
与传统的注意力机制不同,MLA 引入了一个潜在空间,充当输入和输出注意力计算之间的中介。
这种方法大大降低了计算复杂性,同时保持甚至提高了性能。
该系统的工作原理是首先将输入数据投影到压缩的潜在空间中,其中保留关键信息模式但过滤掉冗余数据。
然后,这种压缩表示会经过多头注意力处理,从而使模型能够同时从各个角度考虑信息的不同方面。
结果是对复杂数据模式的理解更加有效和细致。
DeepSeekMoE 架构
DeepSeekMoE(混合专家)架构彻底改变了 AI 模型处理不同类型任务的方式。
该系统没有采用一刀切的方法,而是采用了多个专门的神经网络(专家),每个网络都擅长处理特定类型的问题或数据模式。
复杂的路由机制决定哪个专家或专家组合应该处理每个输入。
这种架构可以显著提高效率,因为对于任何给定的任务,只需要激活模型总参数的一小部分。
该系统动态平衡专家之间的工作量,防止出现瓶颈并确保最佳资源利用率。
事实证明,这种方法在处理多样化任务并保持高性能标准方面特别有效。
多标记预测(MTP)
多标记预测系统通过同时预测多个标记而不是一次预测一个标记来增强模型生成响应的能力。
这一进步在不牺牲准确性的情况下显著提高了处理速度。
该系统通过保持对标记之间的上下文和依赖关系的复杂理解来实现这一点,从而使其能够对标记序列而不是单个标记做出准确的预测。
FP8 混合精度训练
这种创新的训练方法使用 8 位浮点格式以及传统的更高精度格式,大大降低了内存要求和计算成本。
系统动态确定哪些计算需要高精度,哪些计算可以以较低的精度执行而不会影响模型性能。
这样可以缩短训练时间并降低资源需求,同时保持模型准确性。
DeepSeek-V3 基准测试性能
DeepSeek-V3在多个基准测试中取得了最佳成绩:
先进的训练方法
无监督微调的强化学习
DeepSeek 的纯强化学习方法代表了人工智能训练的范式转变。系统不再依赖标记数据,而是通过交互和反馈进行学习。
该模型通过反复试验来加深其理解,成功的结果会得到奖励,犯错则会受到惩罚。
这种方法可以产生更加强大和适应性更强的人工智能系统,可以更有效地处理新情况。
学习过程涉及几个复杂的机制:
- 自我验证系统:模型开发内部检查来验证自己的推理
- 模式识别:学习识别和利用数据中的复杂模式
- 自适应学习:系统根据过去的表现调整学习策略
- 自主改进:无需直接监督,持续改进能力
冷启动集成
冷启动过程谨慎引入初始训练数据,为模型提供知识基础。这些数据经过精心挑选,以确保质量和相关性,同时避免偏差。该过程包括:
- 初始知识库:跨多个领域精心挑选的高质量数据
- 结构化学习进度:逐步引入越来越复杂的概念
- 平衡管理:确保不同类型的知识均匀分布
- 质量控制:严格验证训练数据和结果
高级奖励模型
奖励建模系统使用复杂的指标来评估模型性能并指导学习。该系统考虑了多种因素:
- 输出质量:评估响应的准确性和相关性
- 推理过程:评估得出结论的逻辑步骤
- 效率:衡量计算资源利用率
- 一致性:确保不同任务的稳定性能
性能优化
语言一致性增强
语言一致性系统确保在不同语境下使用语言的连贯性和恰当性。这包括:
- 语境意识:理解并保持适当的语言风格
- 结构完整性:确保语法和逻辑的一致性
- 文化敏感性:使语言的使用适应不同的文化背景
- 领域适当性:在需要时维护适当的技术词汇
模型提炼过程
提炼过程将知识从较大的模型转移到较小的模型,同时保留关键功能。这包括:
- 知识压缩:识别并保存基本模式
- 性能优化:减少参数,保持高精度
- 效率提升:提高速度和资源利用率
- 能力保存:确保维护关键功能
DeepSeek-R1 与 OpenAI-o1:直接比较
虽然OpenAI-o1在通用 AI 能力方面保持了优势,但 DeepSeek-R1 提供了一种引人注目的替代方案,特别是对于研究驱动的应用而言:
DeepSeek-R1 的主要优势在于其开源特性,允许研究人员和开发人员针对各种应用试验和改进模型。
未来发展领域
增强多模式学习
该系统的多模式学习能力正在扩展,以处理各种类型的输入:
- 视觉处理:高级图像理解和生成
- 音频分析:复杂的声音处理和语音识别
- 文本集成:改进自然语言理解和生成
- 跨模式学习:更好地整合不同模式间的信息
高级解决问题的能力
未来的发展重点是增强模型的解决问题的能力:
- 复杂推理:处理多步骤逻辑问题
- 创造性解决方案:提出应对挑战的新方法
- 适应:将学到的知识应用到新情况中
- 验证:改进自检和确认机制
结论
这些技术创新代表了人工智能发展的重大进步,使 DeepSeek 处于人工智能研究的最前沿。复杂的架构、先进的训练方法和持续的优化工作相结合,创造了一个强大而灵活的人工智能系统,能够应对各种挑战,同时保持高性能标准。
未来的发展路线图表明,未来将有更多令人印象深刻的功能,重点是实际应用和解决实际问题。随着这些技术的不断发展,它们可能会对从科学研究到日常应用的各个领域产生越来越重大的影响。
常见问题解答
- 1、DeepSeek 与传统 AI 模型有何不同? DeepSeek 以其独特的强化学习方法脱颖而出,无需监督微调,尤其是在其 R1-Zero 模型中。与依赖预先标记的数据集的传统模型不同,DeepSeek 通过经验和自我发现自主学习,类似于儿童自然学习的方式。
- 2、DeepSeek 家族主要有哪些组件呢? DeepSeek 家族主要由三个组件组成:DeepSeek-R1-Zero(纯强化学习模型)、DeepSeek-R1(混合学习模型)、DeepSeek-V3(具有 671B 参数和增强处理能力的高级架构)。
- 3、DeepSeek-V3 的多头潜在注意力 (MLA) 如何工作? MLA 的工作原理是将输入数据投射到压缩的潜在空间中,其中保留关键信息,同时过滤掉冗余数据。然后,此压缩表示经过多头注意力处理,允许同时从各个角度考虑信息,从而实现更高效的处理。
- 4、什么是 DeepSeekMoE 架构?为什么它如此重要? DeepSeekMoE(专家混合)是一种使用多个专门的神经网络(专家)来处理不同类型的任务的架构,而不是采用一刀切的方法。这可以提高效率,因为只有相关的专家才会被激活来完成特定的任务,从而减少计算资源,同时保持高性能。
- 5、多标记预测如何增强 DeepSeek 的性能?多标记预测允许 DeepSeek 同时预测多个标记,而不是一次预测一个,从而显著提高处理速度。它通过理解标记之间的上下文和依赖关系来保持准确性,从而能够准确预测标记序列。
- 6、什么是 FP8 混合精度训练?它有哪些优势? FP8 混合精度训练使用 8 位浮点格式以及传统的更高精度格式。通过动态确定哪些计算需要高精度以及哪些可以使用较低的精度,可以降低内存需求和计算成本,从而缩短训练时间并保持准确性。
- 7、DeepSeek 的冷启动集成过程如何工作?冷启动过程涉及谨慎地引入初始训练数据,为模型提供基础知识。这包括精心挑选的跨多个领域的高质量数据、结构化的学习进程、均衡的知识分布以及对训练数据和结果的严格验证。
- 8、与其他 AI 模型相比,DeepSeek 取得了哪些基准测试成绩? DeepSeek 在各种基准测试中都取得了令人瞩目的成绩,包括在 AIME 2024(79.8%)、MATH-500(97.3%)、Codeforces(96.3%)和 MMLU(90.8%)中的高性能,可与 OpenAI 的模型直接竞争。
- 9、DeepSeek 的开源特性如何使 AI 社区受益? DeepSeek 的开源特性使研究人员和开发人员能够针对各种应用试验和改进模型,通过社区协作促进 AI 研究的创新和进步。
- 10、DeepSeek 的奖励建模系统有何独特之处? DeepSeek 的奖励建模系统使用复杂的指标来评估性能,考虑输出质量、推理过程、效率和一致性等因素。这种全面的评估有助于指导模型的学习和改进。
- 11、DeepSeek 如何处理不同语境中的语言一致性? DeepSeek 通过考虑语境意识、结构完整性、文化敏感性和领域适当性的系统来保持语言一致性,确保在各种情况下使用连贯且适当的语言。
- 12、DeepSeek 未来的发展领域是什么?未来的发展领域包括增强多模式学习(视觉、音频、文本处理)、高级问题解决能力、复杂推理、创造性解决方案以及改进的自检机制。
- 13、DeepSeek 的模型蒸馏过程是如何工作的?模型蒸馏过程将知识从较大的模型转移到较小的模型,同时通过知识压缩、性能优化、效率提升和能力保留来保留关键能力。
- 14、DeepSeek-R1-Zero 面临的主要挑战是什么?虽然 DeepSeek-R1-Zero 表现出了强大的推理能力,但由于其采用纯强化学习方法而没有监督微调,因此在沟通清晰度和一致性方面面临挑战。
- 15、DeepSeek 在通用能力方面与 OpenAI 的模型相比如何?虽然 OpenAI 在通用 AI 能力方面占据优势,但 DeepSeek 提供了一种引人注目的替代方案,特别是对于研究驱动的应用程序而言,在许多基准测试中具有可比的性能,并且具有开源的优势。
作者:
珠海东道
来源:
本文章来源于网络,主要目的在于分享信息,版权归原作者所有,如有涉及侵权请联系删除谢谢!
文章推荐






PARTNER

成为合作伙伴
期待与您的合作

珠海市东道信息技术有限公司
电话:0756-2252006 / 0756-2252055
手机:18023086166 / 13539556536(孙先生)
18023093616(朱先生)
13823081550(谢小姐)
15676730263(丘小姐)
邮箱:627935592@qq.com
地址:珠海香洲区凤凰南路1038号海城大厦1606房
© 东道信息技术 粤ICP备20022794号

0756-2252006
地址:珠海市香洲区凤凰南路1038号海城大厦1606室
电话:0756-2252006 / 0756-2252055
手机:18023086166 (孙先生) 13539556536(于先生) 13823081550(谢小姐)18023093613(朱先生)
邮箱:624732830@qq.com

业务咨询微信

公司手机网站
版权所有 © 珠海市东道信息技术有限公司 - 网站ICP备案:粤ICP备20022794号 -  粤公网安备44040202001632号 免责声明
粤公网安备44040202001632号 免责声明
网站建设:超凡科技

 客服1
客服1
